Choosing Between Web Scraping APIs and Custom ETL Pipelines
Data is abundant. Advantage is rare.
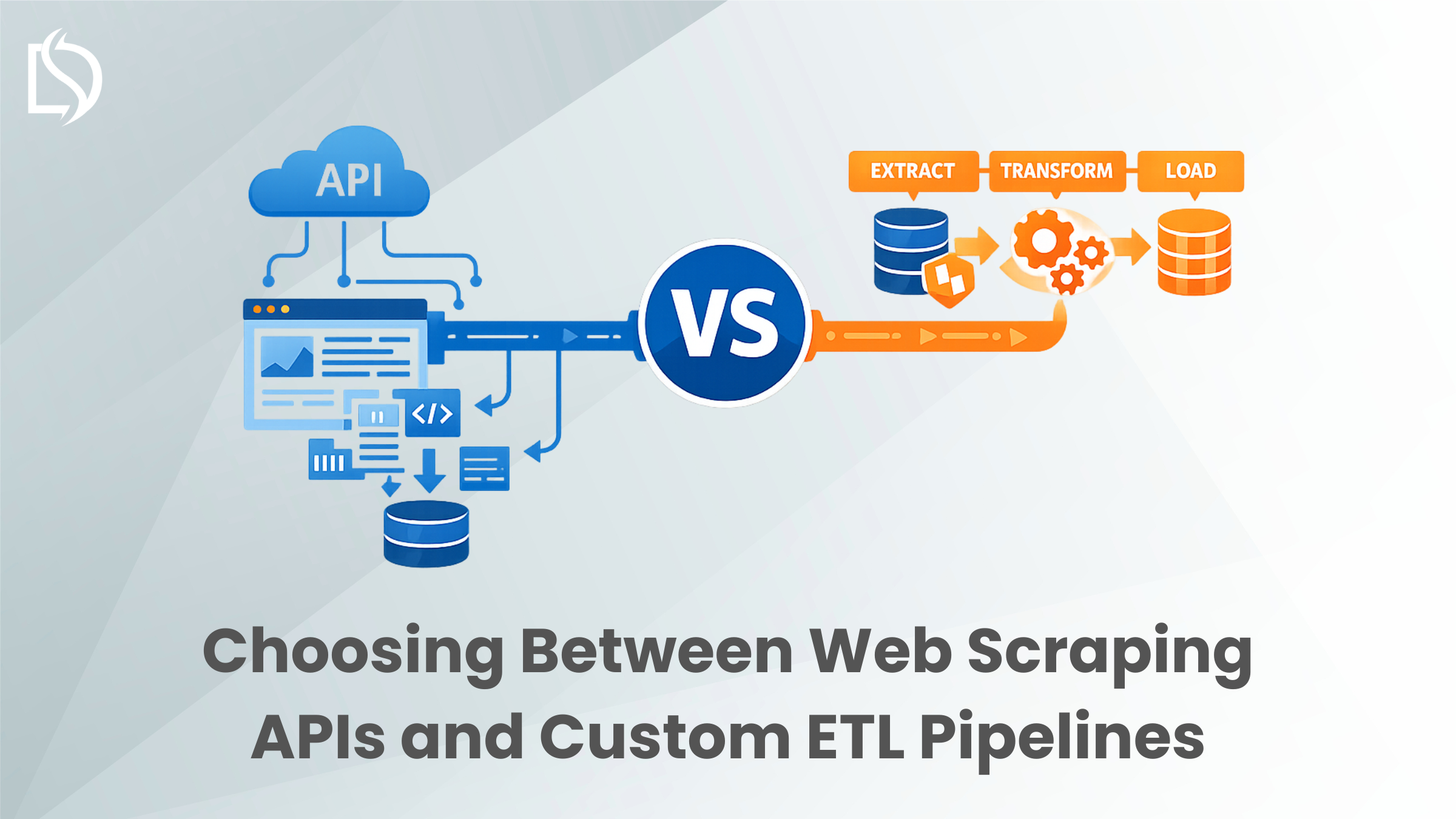
For most CTOs and data leaders, the bottleneck isn’t getting access to data; it’s the architecture used to retrieve it. When building a data strategy, you are often faced with a binary choice: Do you deploy an off-the-shelf Web Scraping API for quick access, or do you invest in a Custom ETL Pipeline?
Ultimately, you are usually forced to decide between “Deployment Speed” and “Strategic Value”. Deployment Speed will provide you with a temporary solution to get something done quickly. Strategic Value will create long-term competitive advantage.
Here is a deep dive into which architecture actually supports high-volume business needs and which one might be silently costing you millions.
Option 1: The Web Scraping API (The “Fast” Lane)
Essentially, a Web Scraping API is a “rental service”. You send a request to a third-party vendor who takes care of proxy rotation and CAPTCHA solving and returns the raw HTML or JSON from the target website.
- Best for: Projects requiring one-time access to a single source; low-volume requests for data; Teams without any internal technical infrastructure.
- The Trap: APIs handle access, not processing. They deliver raw materials, not a finished product.
The “So What?” Factor
While APIs are fast to deploy, they shift the burden of cleaning and structuring data onto your internal team. You save money on extraction but bleed budget on transformation.
Option 2: The Custom ETL Pipeline (The “Strategic” Lane)
A custom-built ETL pipeline (Extract, Transform, Load), is an owned system. It does not simply retrieve data; it also cleanses, validates and formats it to meet your company’s unique proprietary business rules before being placed into your databases.
- Best for: Enterprises with high-volume data requirements; Organisations in need of using predictive analytics; Companies seeking to utilise historical verified intelligence as the basis for developing future business strategies.
- The Advantage: You own the logic. If a target site changes, your pipeline adapts. If your business rules change, your data structure evolves with them.
The “So What?” Factor
An ETL pipeline turns “raw data” into “integration-ready assets.” This allows your data scientists to apply critical insights immediately, rather than spending weeks cleaning messy JSON files.
The Hidden Costs of the Wrong Choice
Many businesses choose APIs to save upfront development time, only to hit a “Strategy Ceiling” later. Here are the three data pitfalls that occur when you choose the wrong architecture.
1. The Transformation Trap (Opportunity Cost)
If you use a standard API, you get raw data. This forces your expensive data science team to become data janitors.
- The Data: Industry studies consistently show that According to Industry Consensus, Data Science/Analytics teams typically waste approximately 80% of their time cleaning data as opposed to extracting actionable intelligence from the cleaned data.
- The Impact: Your best talent is stuck fixing formatting errors instead of building the predictive models that drive revenue.
2. The Maintenance Mirage (Data Decay)
APIs are often black boxes. When they break, you wait for the vendor to fix them. Custom pipelines, however, are engineered for resilience and self-healing (Change-detection automation).
- The Data: One study found that 85% of companies blamed stale data for bad decision-making and lost revenue. Pipeline breakage is a direct driver of this decay.
- The Impact: If your data flow stops, your decision-making stalls. “Stale” data is worse than no data; it leads to confident errors.
3. The Trust Deficit (Governance Failure)
Without the deep governance controls of a custom pipeline, data quality fluctuates. This erodes executive confidence.
- The Data: An alarming 58% of business leaders report that key business decisions are based on inaccurate or inconsistent data (SoftServe).
- The Impact: When leaders don’t trust the data, they revert to “gut feeling,” rendering your entire data investment useless.
Summary: Which One Wins?
| Feature | Web Scraping API | Custom ETL Pipeline |
| Speed to Deploy | High (Days) | Medium (Weeks) |
| Data Quality | Raw / Unstructured | Clean / Validated |
| Maintenance | Vendor-dependent | Owned & Automated |
| Strategic Value | Descriptive (Reporting) | Predictive (Commanding) |
| Ideal For | Ad-hoc / Low Volume | Enterprise / High Scale |
Final Verdict
If your goal is simple extraction, use an API. But if your goal is shaping future strategies with high-volume, verifiable, and integrated data, a Custom ETL pipeline is the only viable architectural choice.
SUBSCRIBE TO OUR NEWSLETTER
RECENT POSTS
 What Is RPA? A Strategic Guide for Business Leaders
What Is RPA? A Strategic Guide for Business Leaders- From OLTP to OLAP: Designing a Modern Data Stack for Enterprise Agility
- The Impact of AI in Bulk Data Scraping and the Rise of Autonomous Agents
- The Role of Real Estate Data in Decision Making
- Architecting Proxy Chains for Distributed Traffic Flow in Akamai-Protected Environments




